WP - Diseño Web - Panel de carga (loading panel)
Hola nuevamente. Tratando de manternerme conectado, (y mientras espero a que se termine de instalar SQL Server), en esta ocasión quiero compartirles una forma bastante sencilla de hacer un panel de cargado con CSS y javascript. El panel de cargado usualmente es un componente que se utiliza para invalidar un área determinada de la página web mientras se realiza algún proceso, para evitar que el usuario realice alguna acción dentro de dicha área.
El panel que les mostraré básicamente es un DIV que poseerá un GIF animado como indicador de procesamiento. Este “panel” se superpondrá a otro elemento DIV, que es el área a invalidar.
Primeramente, este es el HTML de la página web:
Obsérvese que el DIV que se desea invalidar es el que posee el ID "area_invalidar". Dentro de este se ha colocado el DIV que servirá de panel de cargado, como primer elemento hijo (ID="panel_carga").
Luego, tenemos el archivo CSS ("estilos.css"):
La parte de mayor interés está marcada entre los comentarios "Clases CSS de interés". Nótese que el DIV que representa el área a invalidar tendrá la propiedad position con el valor relative, mientras que el DIV que será nuestro panel de carga tendrá el valor de absolute. Esto se debe a que queremos indicar que las propiedades de posición y tamaño del DIV panel de carga serán relativas con respecto al DIV área a invalidar. Gracias a ello podemos especificar el ancho y alto del DIV panel de carga como 100%, para indicar que éste ocupará todo el espacio del área a invalidar.
Luego, en la misma clase utilizada para el panel de carga, tenemos la propiedad de opacidad (alpha para Internet Explorer, opacity para Mozilla Firefox y otros), con la cual especificamos la razón o porcentaje de opacidad del panel de cargado. Al combinarla con un color de fondo (background-color) se logra un efecto de oscurecimiento y transparencia sobre el área invalidada. Adicionalmente a ello se coloca una imagen de fondo, que en este caso es un GIF animado, mediante la propiedad background-image, para que muestre al usuario un indicador de que se está realizando alguna clase de procesamiento. La imagen es centrada y aparece solamente una vez, gracias a las propiedades background-position:center y background-repeat:no-repeat, respectivamente.
También se tiene la propiedad z-index, que indica la “altura” o nivel del elemento. Dicha propiedad tiene significado dentro del elemento padre, por lo que tiene influencia para todos los nodos hermanos. El valor por defecto es cero, por lo que al colocar un valor de, por ejemplo, 10, nos aseguramos de que el panel de cargado estará sobre el resto de elementos contenidos en el DIV de área a invalidar.
Finalmente tenemos la propiedad de visibilidad, que le colocamos el valor de hidden, para que el panel de carga aparezca oculto al mostrarse la página.
Por otra parte se tiene el archivo de código fuente de Javascript. El javascript es necesario para realizar el cambio de las propiedades CSS a través de las acciones del usuario.
En este caso, según puede observarse en la página HTML (arriba), al presionar el botón "Enviar" se ejecutará la función procesar, que recibe como parámetro el ID del DIV que sirve de panel de carga. Dicha función básicamente se encarga de mostrar el DIV de carga.
Nótese que para efectos demostrativos, al final de la función se colocó una llamada a la función setTimeout, para que el panel de cargado se oculte después de 5 segundos. En una aplicación web real, el panel debería de ocultarse una vez se haya obtenido alguna respuesta o resultado después del proceso solicitado.
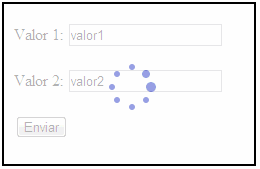
Este es el resultado final, antes de presionar el botón:

Luego de presionar el botón, nótese el aparecimiento del panel de cargado solamente sobre el área a invalidar, que para efectos de este ejemplo corresponde al mismo formulario web:

Finalmente después de 5 segundos se oculta el panel de cargado, gracias al uso de la función SetTimeOut.
Como pueden observar este método es una forma fácil, rápida y directa de crear un panel de cargado DIV, utilizando solamente HTML, CSS y javascript puros.
Les debo el código fuente para descargar, ya que lo dejé en otra computadora que he prestado por el momento.
Saludos.
Publicado originalmente el 13/02/2013, en https://itsouvenirs.wordpress.com/2013/02/13/diseno-web-panel-de-carga-loading-panel/.